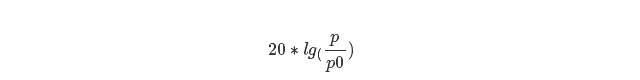检信智能ALLEMOTION OS 语音情感识别——语音(声音的预处理)
日期:2021.09.20 来源:湖南检信智能


检信智能ALLEMOTION OS 语音情感识别——语音(声音的预处理)

1. 语音信号(声音是什么)
声音是由物体振动产生的声波,是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象,最初发出振动的物体叫声源。声音(语音消息)的基本模拟形式是一种称为语音信号的声学波。语音信号可以通过麦克风转化成电信号,转换成语音波形图,如下图为消息"should we chase"的波形图。横坐标表示时间,纵坐标表示振幅。文本"should we chase"按照发音可以表示成音素的形式[SH UH D - W IY - CH EY S],声波图中的每一段表示一个音素,在ARBAbet音素集中包含近64 = 2^6个符号。
声音作为波的一种,频率(声源在一秒内振动的次数)和振幅是描述波的重要属性,频率的大小与我们通常所说的音高对应,而振幅影响声音的大小。声音可以被分解为不同频率不同强度正弦波的叠加,正弦波是频率成分最为单一的一种信号,任何复杂信号都可以看成由许许多多频率不同、大小不等的正弦波复合而成。这种变换(或分解)的过程,称为傅立叶变换,通过这种分解我们可以把时域图转为频域图。
正弦信号表达式为y=Asin(ωx+φ)y=Asin(ωx+φ)。其中A表示振幅。
ω/2πω/2π表示频率。
对于(空气中的)声振动而言,振幅是声压与静止压强之差的最大值。其中声压是声波在空气中传播时形成压缩和稀疏交替变化的压力增值。麦克风录制声音的原理就是将空气中的压力变动波转化成电信号的变动。
而我们平常说的声音强度(响亮程度)就是由振幅决定的,声音强度的单位是分贝(dB),计算公式如下,用实测声压和参考声压之比的常用对数(常用对数lg以10为底,自然对数ln以e为底)的20倍来表示。下式中分母是参考值的声压,通常为20微帕,人类能听到的最小声压。
分贝表示功率量之比时,等于功率强度之比的常用对数的10倍。
分贝表示场量之比时,等于场强幅值之比的常用对数的20倍。
语音链(声音是怎么发出的)
从语音信号的产生到感知的过程称为语音链,如下图所示:
2 下面是语音信号产生的四个步骤:
文本:消息以某种形式出现在说话者的大脑中,消息携带的信息可认为有着不同的表示形式,例如最初可能以英语文本的形式表示。假设书面语有32个符号,也就是2^5,用5个bit表示一个符号。正常的平均说话速率为15个符号每秒。上图例子中有15个字母“should we chase”,持续了0.6秒,信息流的速率为15x5/0.6 = 125 bps。
音素:为了"说出"这条消息,说话者隐式地将文本转换成对应口语形式的声音序列的符号表示,即文本符号转成音素符号,音素符号用来描述口语形式消息的基本声音及声音发生的方式(即语速和语调)。ARBAbet音素集中包含近64 = 2^6个符号,用6个bit表示一个音素,上图例子中有8个音素,持续了0.6秒,信息流的速率为8x6/0.6 = 80 bps,考虑描述信号韵律特征的额外信息(比如段长,音高,响度),文本信息编码成语音信号后,总信息速率需要再加上100bps。
发音:神经肌肉系统以一种与产生口语形式消息及其语调相一致的方式,移动舌头,唇,牙齿,颌,软腭,使这些声道发声器官按规定的方式移动,进而发出期望的声音。
刺激共振:声道系统产生物理生源和恰当的时变声道形状,产生上图所示的声学波形。
前两个阶段的信息表示是离散的,用一些简单假设就可以估计信息流的速率。
但是后两个阶段信息是连续的,以关节运动的形式发出,想要度量这些连续信息,需要进行恰当的采样和量化获得等效的数字信号,才能估计出数据的速率。事实上,因为连续的模拟信号容易收到噪声的影响,抗噪能力弱,通常会转为离散的数字信号。
在第三阶段,进行采样和量化后得到的数据率约为2000bps。
在最后一个阶段,数字语音波形的数据率可以从64kbps变化到700kbps。该数据是通过测量“表示语音信号时为达到想要的感知保真度”所需要的采样率和量化计算得到的。
比如,“电话质量”的语音处理需要保证宽带为0~4kHz,这意味着采样率为8000个样本每秒(根据香农采样定理,为了不失真地恢复模拟信号,采样频率应该不小于模拟信号频谱中最高频率的2倍),每个样本可以量化成8比特,从而得到数据率64000bps。这种表示方式很容易听懂,但对于大多数倾听者来说,语音听起来与说话者发出的原始语音会有不同。
另一方面,语音波形可以表示成“CD质量”,采用44100个样本每秒的采样率,每个样本16比特,总数据率为705600bps,此时复原的声学波听起来和原始信号几乎没有区别。
现在在音乐app上下载歌曲的时一般有四种音乐品质选择,标准(128kbps),较高(192kbps),极高(320kbps),无损品质。
将消息从文本表示转换成采样的语音波形时,数据率会增大10000倍。这些额外信息的一部分能够代表说话者的一些特征比如情绪状态,说话习惯等,但主要是由简单采样和对模拟信号进行精细量化的低效性导致的。因此,处于语音信号固有的低信息速率考虑,很多数字语音处理的重点是用更低的数据率对语音进行数字表示(通常希望数据率越低越好,同时保证重现语音信号的感知质量满足需要的水平)。
3 语音信号中的Analog-Digital Converter,“模-数”变换(声音是怎么保存的)
预滤波(反混叠滤波):语音信号在采样之前要进行预滤波处理。目的有两个,一是抑制输入信号各频率分量中频率超过fs/2的所有分量(fs为采样频率),以防止混叠干扰;二是抑制50Hz的电源工频干扰。
1.采样:原始的语音信号是连续的模拟信号,需要对语音进行采样,转化为时间轴上离散的数据。
采样后,模拟信号被等间隔地取样,这时信号在时间上就不再连续了,但在幅度上还是连续的。经过采样处理之后,模拟信号变成了离散时间信号。
采样频率是指一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实越自然。
在当今的主流采集卡上,采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级,22.05KHz只能达到FM广播的声音品质,44.1KHz则是理论上的CD音质界限(人耳一般可以感觉到20-20K Hz的声音,根据香农采样定理,采样频率应该不小于最高频率的两倍,所以40KHz是能够将人耳听见的声音进行很好的还原的一个数值,于是CD公司把采样率定为44.1KHz),48KHz则更加精确一些。
对于高于48KHz的采样频率人耳已无法辨别出来了,所以在电脑上没有多少使用价值。
2.量化:进行分级量化,将信号采样的幅度划分成几个区段,把落在某区段的采样到的样品值归成一类,并给出相应的量化值。根据量化间隔是否均匀划分,又分为均匀量化和非均匀量化。
均匀量化的特点为“大信号的信噪比大,小信号的信噪比小”。缺点为“为了保证信噪比要求,编码位数必须足够大,但是这样导致了信道利用率低,如果减少编码位数又不能满足信噪比的要求”(根据信噪比公式,编码位数越大,信噪比越大,通信质量越好)。
通常对语音信号采用非均匀量化,基本方法是对大信号使用大的量化间隔,对小信号使用小的量化间隔。由于小信号时量化间隔变小,其相应的量化噪声功率也减小(根据量化噪声功率公式),从而使小信号时的量化信噪比增大,改善了小信号时的信噪比。
量化后,信号不仅在时间上不再连续,在幅度上也不连续了。经过量化处理之后,离散时间信号变成了数字信号。
3.编码:在量化之后信号已经变成了数字信号,需要将数字信号编码成二进制。“CD质量”的语音采用44100个样本每秒的采样率,每个样本16比特,这个16比特就是编码的位数。
采样,量化,编码的过程称为A/D转换,如下图所示。反过程为D/A转换,因为A/D之前进行了预滤波,D/A转换后面还需要加一个平滑滤波器。A/D转换,D/A转换,滤波这些功能都可以用一块芯片来完成,在市面上能买到各种这样的芯片。
4 语音信号的预处理(声音的预处理)
语音信号的预处理一般包括预加重,分帧,加窗,端点检测。
预加重:求语音信号频谱(频谱是指时域信号在频域下的表示方式,关于频域和时域的理解如下图所示),频率越高相应的成分越小,高频部分的频谱比低频部分的难求,为此要在预处理中进行预加重(Pre-emphasis)处理。预加重的目的是提高高频部分,使信号的频谱变得平坦,以便于频谱分析或者声道参数分析。预加重可在语音信号数字化时在反混叠滤波器之前进行,但一般是在语音信号数字化之后。
短时分析:语音信号从整体来看是随时间变化的,是一个非平稳过程,不能用处理平稳信号的数字信号处理技术对其进行分析处理。但是,由于不同的语音是由人的口腔肌肉运动构成声道某种形状而产生的响应,这种运动对于语音频率来说是非常缓慢的,所以从另一方面看,虽然语音信号具有时变特性,但是在一个短时间范围内(一般认为在10-30ms)其特性基本保持相对稳定,即语音具有短时平稳性。所以任何语音信号的分析和处理必须建立在“短时”的基础上,即进行“短时分析”。
分帧:为了进行短时分析,将语音信号分为一段一段,其中每一段称为一帧,一般取10-30ms,为了使帧与帧之间平滑过渡,保持连续性,使用交叠分段的方法,可以想成一个指针p从头开始,截取一段头为p,长度为帧长的片段,然后指针p移动,移动的步长就称为帧移,每移动一次都截取一段,这样就得到很多帧。
加窗:加窗就是用一定的窗函数w(n)来乘s(n),从而形成加窗语音信号sw(n)=s(n)∗w(n),常用的窗函数是矩形窗和汉明窗,用矩形窗其实就是不加窗,窗函数中有个N,指的是窗口长度(样本点个数),对应一帧,通常在8kHz取样频率下,N折中选择为80-160(即10-20ms持续时间)。
端点检测:从一段语音信号中准确地找出语音信号的起始点和结束点,它的目的是为了使有效的语音信号和无用的噪声信号得以分离。对于一些公共的语音数据集可以不做这步操作,因为这些语音的内容就是有效的语音信号(可以认为研究人员已经对数据做过端点检测)。
语音信号的特征(声音的特征)
特征的选取是语音处理的关键问题,特征的好坏直接影响到语音处理(比如语音识别)的精度。然而在语音领域中,没有一个所谓的标准特征集,不同的语音系统选取的特征组合不尽相同。
语音的特征一般是由信号处理专家定义的,比较流行的特征是MFCC(梅尔频率倒谱系数)。
5 语音情感识别算法
常用的机器学习分类器:模式识别领域的诸多算法(传统)都曾用于语音情感识别的研究,比如GMM(高斯混合模型),SVM,KNN,HMM(隐马尔可夫模型)。用LLDs(low level descriptors)和HSFs(high level statistics functions)这些手工设计特征去训练。
声谱图+CRNN:最近很多人用声谱图加上CNN,LSTM这些深度学习模型来做。还有手工特征加声谱图一起作为特征放进深度学习模型。也有人用DBN,但是不多。
3.手工特征+CRNN:也有人用手工特征加CRNN做。
————————————————
版权声明:本文为CSDN博主「醒了的追梦人」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。



检信智能公众号